Large-scale iterated singing experiments reveal oral transmission mechanisms underlying music evolution
Abstract
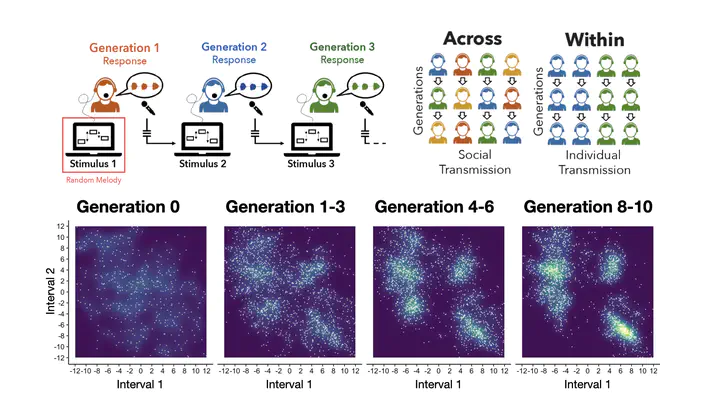
Speech and song have been transmitted orally for countless human generations, changing over time under the influence of biological, cognitive, and cultural pressures. Cross-cultural regularities and diversities in human song are thought to emerge from this transmission process, but testing how underlying mechanisms contribute to musical structures remains a key challenge. Here, we introduce an automatic online pipeline that streamlines large-scale cultural transmission experiments using a sophisticated and naturalistic modality: singing. We quantify the evolution of 3,424 melodies orally transmitted across 1,797 participants in the United States and India. This approach produces a high-resolution characterization of how oral transmission shapes melody, revealing the emergence of structures that are consistent with widespread musical features observed cross-culturally (small pitch sets, small pitch intervals, and arch-shaped melodic contours). We show how the emergence of these structures is constrained by individual biases in our participants—vocal constraints, working memory, and cultural exposure—which determine the size, shape, and complexity of evolving melodies. However, their ultimate effect on population-level structures depends on social dynamics taking place during cultural transmission. When participants recursively imitate their own productions (individual transmission), musical structures evolve slowly and heterogeneously, reflecting idiosyncratic musical biases. When participants instead imitate others’ productions (social transmission), melodies rapidly shift toward homogeneous structures, reflecting shared structural biases that may underpin cross-cultural variation. These results provide the first quantitative characterization of the rich collection of biases that oral transmission imposes on music evolution, giving us a new understanding of how human song structures emerge via cultural transmission.